“本期关键词:大数据与机器学习”
本期论文题目为“Big Data:New Tricks for Econometrics”,由Google首席经济学家范里安在2014年完成,与第一期一样都属于FINTECH的范畴。继2018年之后,本文在今年仍然作为金融热点文章出现,因为文中谈到的机器学习法作为分析大数据很热门的新方法运用到了越来越广的领域。具体可以分为三个部分来理解:
◆ ◆ ◆ ◆ ◆
传统数据分析V.S.机器学习法
第一部分介绍了调用和分析大数据的工具,主要比较了传统数据分析与机器学习法各自的特点。
首先文章给出了传统方法的劣势,即传统统计学用样本回归分析一些小规模的数据很有效,但是面对真正更加庞杂的大数据会出现问题:本身工具容量太小;回归模拟需要选择更多的变量;对于非线性的复杂关系就会显得很吃力。

接下来就是对传统方法与机器学习这样的新方法的比较:
![]() 传统的数据分析可以分为四个步骤:预测、概括、估计和假设检验,而机器学习最关注的是预测未来。
传统的数据分析可以分为四个步骤:预测、概括、估计和假设检验,而机器学习最关注的是预测未来。
![]() 传统的数据分析工具致力于找出数据中的规律,而机器学习更关注的是计算能力,即开发计算机的运算性能。
传统的数据分析工具致力于找出数据中的规律,而机器学习更关注的是计算能力,即开发计算机的运算性能。
![]() 传统用于概括总结规律的方法经常是线性分析,而机器学习提供了一系列的工具来分析大数据中更多样的非线性关系。这些工具包括:分类和回归树(CART方法);随机森林;惩罚回归等。
传统用于概括总结规律的方法经常是线性分析,而机器学习提供了一系列的工具来分析大数据中更多样的非线性关系。这些工具包括:分类和回归树(CART方法);随机森林;惩罚回归等。
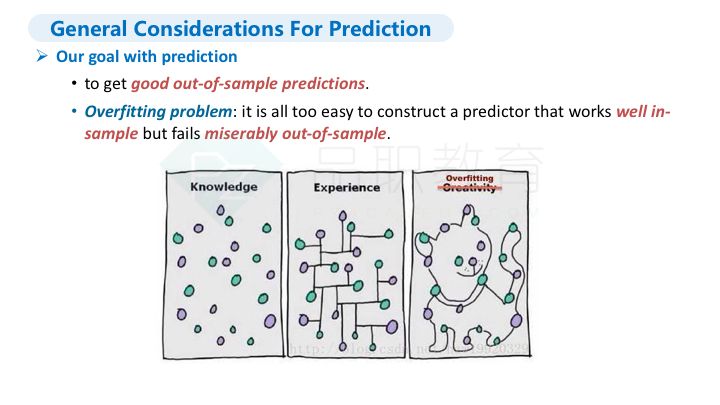
另外需要注意的是,机器学习预测数据的目标主要有两个,一个是获取优质的样本外预测,一个是解决过度拟合问题(overfitting problem)。解决过度拟合问题的方法主要有:少用复杂模型;将数据按training、testing、validation分类;交叉验证k-fold cross-validation。
机器学习的具体应用方法
引入了机器学习的诸多优势之后,文章在第二部分介绍了机器学习的具体应用方法。重点有以下几个:
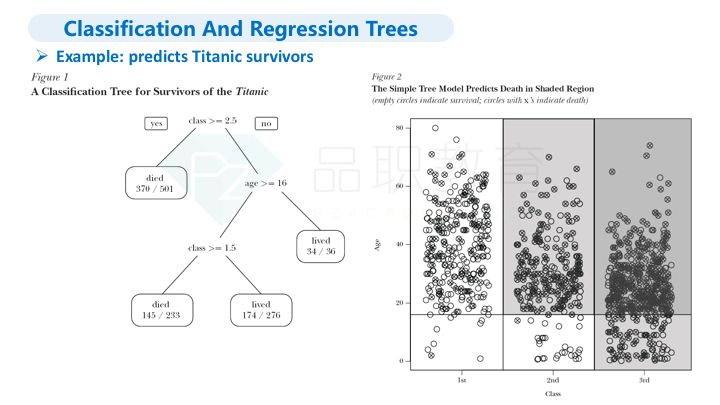
首先是分类和回归树(CART方法)。文章用泰坦尼克幸存者分析作为例子,将船上乘客按舱位和年龄分析死亡率。里面提到一个观点是传统经济学主要是线性回归,所以对一些非线性关系无法做分析,如果用传统分析方法,年龄因素对于死亡率的影响是很低的,但是如果用CART方法,年龄是一个重要的影响因素。

其次,剪枝树法Pruning Trees、随机森林以及其他的方法(Bootstrap,Bagging,Boosting)等都可以作为改进分类方法的补充。
传统计量经济学与机器学习的结合
既然传统计量经济学的方法与机器学习的新方法都各有优劣势,那么在第三部分文章探讨了两者在具体应用中的结合。

我们必须认识到有很多领域都存在计量经济学与机器学习结合运用相互促进的机会。重点有以下两个方面:
首先是因果分析方面,因为机器学习法在探索数据背后逻辑性规律方面存在缺陷,所以结合计量经济学可以促进机器学习对数据的归因分析。
其次在不确定性方面,小数据时代关注的主要是样本的不确定性,而大数据时代更应该关注的是模型的不确定性,所以,将两者结合起来,用多个不同类型的小模型做平均会优于选择单一方法的模型去做分析。
本期文章内容不多,重点突出。奉上思维导图:
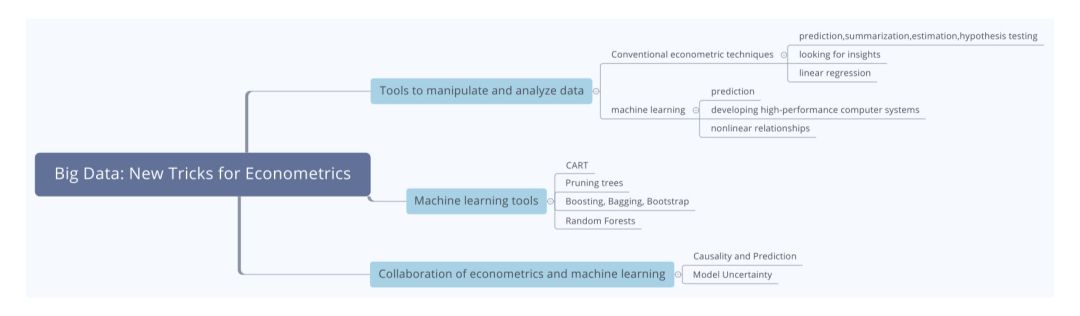
思维导图的高清版在公众号后台回复【2019FM42.5】获取网盘链接。

更详细的讲解可以到喜马拉雅电台来听李老师的课程哦,扫描下方的二维码即可直达!

最后放上本讲的讲义,希望对大家的学习有所帮助哦!
























◆ ◆ ◆ ◆ ◆


配图来源网络


