网络信息时代,我们每个人都仿佛变得越来越透明了。在一个地方填写的个人信息过几天就能被一个完全不相干的第三方知道,电话骚扰还是次要的,甚至有人莫名其妙就多了几个自己都不知道的银行账号……不得不说,网络信息安全和隐私数据保护已经成为金融机构必须重视的问题。

可惜在实践中,信息保护工作一直是个难点,一个是信息时代的全面到来引发的数据大爆炸,另一个是数字时代的信息共享太广泛(具体可以参考这篇文章台风“利奇马”有个啥?来看AI带来的金融圈数据风暴!|品职FINTECH“阔”论沙龙)——诸如电信、交通、教育、医疗、金融、政府机构等多家单位数据联网的共享机制导致难以查证信息泄漏源头、信息披露与信息泄露的边界难以准确判断……如此种种,使得海量的数据监测和管理犹如海底“探”针,难上加难。![]()
好消息是,近几年的研究发现,人工智能(AI)可以帮助金融机构主动检测数据泄露,防止其升级为重大风险事件(比如前两年发生的多个名人家庭住址甚至财务账号等信息在网上公开的事件);还可以模拟数据安全漏洞可能导致的风险事件时间表,作为整个风控预警系统的参考基础。那么,为什么AI可以做到这些呢?

网络小白科普时间
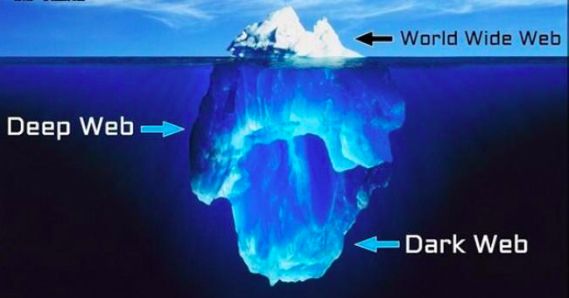
咱们普通大众平时访问的网页地址前段都有“www”意思就是万维网,即world wide web,听起来非常宏大啊,但却只是整个互联网世界的冰山一角。还有很多我们普通用户日常无法触及的地带,被称作DDW即deep web和dark web,中文翻译为深网和暗网。
通俗来讲,深网是指互联网上那些不能被标准搜索引擎抓取到的网络内容,比如个人聊天记录、微信屏蔽所有人的朋友圈、微博私信等不能被公开显示的私有内容。
而暗网呢,是深网中不能通过常规方式、常规浏览器访问的私有网络,比如有些只能用TOR浏览器等等。之所以特殊给它“暗”的名号,是因为它属于网络上的黑市,包含了很多军火买卖、暴力色情内容等非法内容,当然也藏有大量信用卡用户信息等各个金融机构的非公开数据。
图片来源网络
看到这里,大伙儿可能会明白,诸如银行员工一条几十元地售卖客户信息这种实体行为已经属于最low批的泄漏了,其实大量的个人隐私泄漏——包括对每个人日常生活所留下的数字指纹(比如浏览cookies、网上支付记录等等)的批量搬运——都活跃在深网和暗网领域。
当然,DDW的存在本身并不是问题,不公开的网络是必须有的,而且很多金融机构或者其他服务机构为了更好地提升客户体验,也需要对用户群体的特征画像,以及经过用户同意留存和共享他们的浏览记录等信息;但还是有很多个人信息被不法分子用来进行诈骗活动、洗钱、用他人姓名非法注册账户、进行工商登记等等。

所以,互联网迅速发展的今天,在每个国家的金融系统电子化发展过程中,必须要重视起来的风控内容就是对DDW(暗网和深网)网络活动进行监测管理和提前预警。
对海量数据世界的探索需要AI加入
在公众万维网的世界中,我们都听说过有“网警”的存在;那么在更广阔的DDW暗黑网络世界呢?在“冰山之下”的网络中,如何定位网络犯罪分子和其他不良行为者的异常活动?DDW是一个巨大的环境:它不仅具有数十年的数据历史,而且还在众多协议,论坛和资源中以惊人的速度继续增长。从DDW的数百万个文件和PB级(1PB = 250字节; 1024TB或100万GB)的信息中提取相关信息是一项艰巨而复杂的挑战!![]()
这个时候,我们的AI就闪亮登场了!毕竟人们研发和应用机器学习(即AI)的原始动力就是对大数据的分析——面对海量数据世界,是AI的吃饭本领。

前不久,GARP协会向金融机构从业者们宣布,研究人员探索出令人兴奋的人工智能新领域,可以更快地搜索和标记到目标数据并创建有用的模型来推进网络安全工作。
AI“出警”三板斧
1.优化搜索过程
人们可以首先创建一个原信息所在机构特有的关键术语(比如IP地址,域名等),并且通过若干模拟过程训练AI来区分风险相关和不相关的文件,AI就可以在深网和暗网(DDW)中的大量数据中识别出关键术语并且剔除噪音,比如删除包含特定术语但不代表风险的文件(比如大型PDF书籍,媒体采访,营销材料,演讲活动等项目资料),从而提取出真正可能遭到泄漏的信息进行风险标记。![]()

这里非常值得一提的是机器学习的神奇。之所以把AI直接与机器学习划等号,是因为AI的神奇之处就是它可以不断地像人一样“后天”习得很多有用的技能,而且超级高效和准确。已经有研究成果表明,经过训练模型开发出的AI在查找和标记风险数据中的准确率,参考经验丰富的情报分析师得出的结论,已经可以达到99.97%,当然速度要比人类分析师快的多。
2.聚类分析法将“大海捞针”的范围缩小
在前期查找和标记数据的丢失风险和路径上,人们可以利用AI非常轻松地完成,而下一步就可以结合人工判断将被标记的数据进行一块块大类的分组。例如,在一个案例中,人们在DDW中发现了大量航空公司的旅行路线,这表明机构可能存在这个方面的信息安全漏洞。
在这一步,人类分析师可以充分发挥作用,通过总结机构本身信息文本拥有的特征,创建“术语矩阵”,来帮助AI进一步细化查找出的信息集合。

这种被称之为“聚类”分析(clusteringmethod)的方法可以在DDW大量数据存储中发现机构特定的风险指标、缩小有信息泄漏可能的文件集。
3.监测数据丢失的风险
大量聚类分析显示,一般在数据丢失事件发生后,机构在DDW上的相关文件数量就会显著增加。偷窃者将积累文件规模,一旦达到足够数据的阈值,就会打包这一整块信息进行违规活动。
所以,一旦确定机构已经暴露和丢失数据,那么下一阶段将涉及时间线分析,人们会利用AI模拟和预测潜在的违规行为。

利用人机判断相结合的自动化监控系统,人们可以在大量文件集群出现时向机构发出警报。它使得机构能与客户合作,在数据丢失成为更大的事件之前主动检测风险,并查找数据暴露发生在机构内部的哪个位置、揪出可能有的“内鬼”。![]()
总之,将数据调查专业知识与新一代机器学习相结合,可以帮助各个组织机构更好地理解和解决他们在DDW上的数据暴露问题。
而随着研究人员不断完善和发展模型和方法,他们将能够帮助金融机构主动检测数据丢失,并防止这些数据丢失升级为可能在未来几年内损害其运营、财务和声誉的重大事件。





