
所谓机器学习就是利用计算机将纷繁复杂的数据处理成有用的信息,这样便可以挖掘出数据带来的意义以及隐藏在数据背后的规律。
![]() 本期这篇文章主要是讲的是机器学习在风控与合规领域的应用。作者一开始讲了机器学习的过程及其应用,最后为我们详细列举了3个案例分别信用风险评估、反诈骗以及异常交易的识别。这些案例都是平时在风险管理中比较重要的话题。
本期这篇文章主要是讲的是机器学习在风控与合规领域的应用。作者一开始讲了机器学习的过程及其应用,最后为我们详细列举了3个案例分别信用风险评估、反诈骗以及异常交易的识别。这些案例都是平时在风险管理中比较重要的话题。

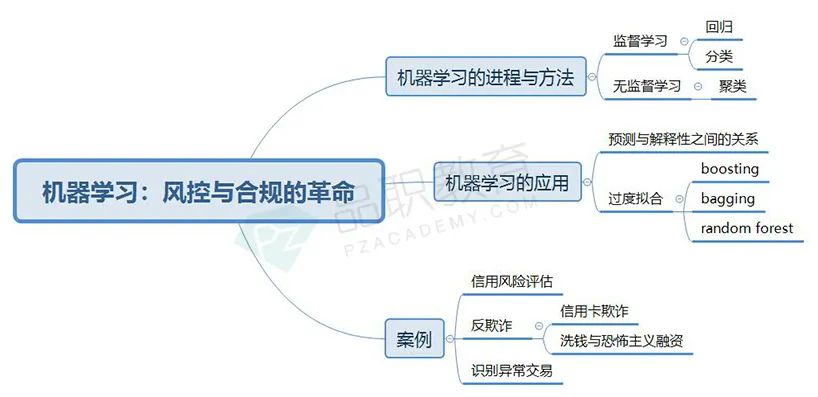
机器学习的进程与方法
机器学习主要应用在大量数据中分析中,可以为人们提供深度的预测分析,它的天然属性让其在风控和机构监管上的应用前景十分广阔。但因为模型存在预测性越强就需要越复杂的模型,其解释力度相应也就越差的问题,所以笔者在开始就明确表示机器学习并不适用于所有领域,在部分领域,机器学习的预测能力有限。
总体来说机器学习可以分为监督性学习与无监督学习。
![]() 监督学习(supervised learning):分组前知道统计变量的区别
监督学习(supervised learning):分组前知道统计变量的区别
![]() 无监督学习(unsupervised learning):事先没有属性的区别
无监督学习(unsupervised learning):事先没有属性的区别
机器学习可以应在三种类别的统计学问题中,分别是:回归、分类、和聚类。其中回归和分类都可以通过监督性学习解决,而聚类问题则要通过无监督式学习。
![]() 回归:找到自变量与因变量间的定量关系,包括线性关系和非线性关系
回归:找到自变量与因变量间的定量关系,包括线性关系和非线性关系
![]() 分类:按照一开始的分类标准将样本分成不同种类。一般采用决策树、支持向量机
分类:按照一开始的分类标准将样本分成不同种类。一般采用决策树、支持向量机
![]() 聚类:事先没有分类标准
聚类:事先没有分类标准
小伙伴们要特别注意分类与聚类的区别,分类在一开始就有明确的区分标准,而聚类并没有,它只是把对象按照一定的相似属性放在一起。比如,作者举例欺诈这个事情就只能采用聚类。我们面对一个事件,只能识别出哪些肯定不是欺诈,然后再把剩下的与欺诈有相似行为的事件归集在一起。对于是否属于欺诈行为,在一开始并没有像男女性别区分一样存在明显的分类标准。

机器学习的应用
作者在第一部分讲了机器学习的原理,第二部分主要讲到的是一些关于机器学习应用的注意事项,主要如下:
预测与解释性之间的关系
机器学习存在解释力度不强的问题。当一个模型的预测性越好,也就意味着它越复杂,解释力度越弱,它的模型更多的是揭示相关性而非因果关系。
过度拟合的问题
过度复杂的模型同样会导致过度拟合问题(即把偶然当必然)。对于解决过度拟合的问题,文章也粗略介绍了几种方法:
![]() boosting(增加对数据的处理观察,以解决数据稀缺性问题)
boosting(增加对数据的处理观察,以解决数据稀缺性问题)
![]() bagging(一个模型要在不同的子样本上运行数千次,最后取平均结果,以提高预测能力)
bagging(一个模型要在不同的子样本上运行数千次,最后取平均结果,以提高预测能力)
![]() random forest(由多个不同的基于决策树模型组成的随机森林)
random forest(由多个不同的基于决策树模型组成的随机森林)
由于机器学习本身缺乏解释力度和其固有的复杂性,单纯依赖过去历史数据而无法预测未来可能的突发事件。作者认为机器学习还可以进一步发展与人工智能、神经网络等其他模型相结合。
案例
最后部分,笔者引用了现实中的三个案例来介绍机器学习的应用
信用风险评估
当下以小微信贷为主的互联网银行的兴起,金融机构开始运用机器学习去优化金融风险的预测。比如阿里巴巴集团在日常为客户服务的同时,就累计了像各位日常在淘宝上的购物,出行交通选择等的大量数据,基于这些数据就可以利过聚类来判断会还贷款的特点与不会还贷款的特点。银行现在虽然拥有了海量的贷款数据作为数据源来分析信贷风险,但在使用中面临的最大的问题仍然是机器学习模型过度复杂引起的过度拟合的问题。

欺骗:信用卡诈骗 、洗钱和恐怖主义融资
机器学习近年来取得重大进展的应用就是关于监测信用卡的欺诈来反欺诈。高频的信用卡交易数据提供了海量的数据源去算法训练、回测以及验证。银行现在针对信用卡诈骗有了一套专门的标签分类。但是从系统中甄别洗钱行为和恐怖融资就不那么简单了。
一方面洗钱不像信用卡交易一样高频且明显,所以数据比较少。另一方面,洗钱也没有明确的定义,对其监管仅保留在机构发现异常后上报这个层面,这样的监管方式也不利于数据的累计。
识别异常交易
异常交易有动作快,破坏力大等特点,所以对于异常交易需要重点监管。随着机器学习对大数据分析的介入,现在对于异常交易的甄别准确率正逐年提升。从过去只能通过系统监测单笔交易的交易行为到现在可以甄别整个交易组合,小到邮件收发、行事历安排,工作打卡以及电话记录……皆能监控。
举个例子:如果一个交易员的行为或者交易表现跟正常的行为有不同,系统会自动发出预警到金融机构的合规组。由于这种数据源也是非事前标签的,所以主要是用于无监督性学习。
以上就是本期内容的要点概述,小编为大家奉上思维导图帮助大家记忆,更加详细的讲解欢迎收听李老师的课程哦。
如果想要更多精彩内容,大家可以到喜马拉雅电台来听李老师的讲解哦,扫描下方的二维码即可直达!(5.1 中午12:00后上传完成)




配图来源网络


戳原文,直接购买「2020品职FRM课程」


