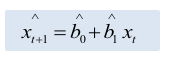NO.PZ2018101001000057
问题如下:
Katy wants to predict the income of his shop in October 20X9, so he uses income of January 20X6 to September 20X9 as samples to make a AR(1) model and gets the following result:

Which of the following statements is least likely correct?
选项:
A.Residuals are serially correlated.
B.Standard error for each of the autocorrelations is 0.1508
C.Standard error for each of the autocorrelations is 0.1491
解释:
C is correct.
考点: Serial correlation of the error term.
解析: 本题要选的是最不正确的一个描述。虽然从20X6年1月到20X9年9月一共有45个月,但是在AR模型里,T=n-1=44。所以自相关的标准误=1/ T =1/ =0.1508,B选项正确,C选项的描述是错误的。A选项正确因为在四个自相关系数中有两个的t统计量都大于临界值,意味着残差项是自相关的。
想问一下这题如果反推,具体应该怎么算
还有什么时候应该是n,什么时候应该是n-1分不太清楚(假设题目没有给observation的情况),麻烦老师解释一下