


问题1:选项B为何不对呢?
问题2:选项C的理解不应该是解决overfiting的问题吗,自变量数据过度可以理解为会造成overfiting吗?
菲菲_品职助教 · 2019年04月13日
同学你好,我们知道这个惩罚项并不等于残差的平方和。
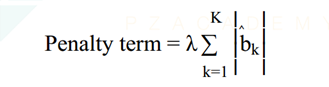 所以B不对。
所以B不对。
惩罚回归是广义线性模型(GLM)的特殊形式,目标在于通过选择模型参数、调整拟合程度来简化模型。简化后的模型往往工作得更好,因为它们不太会出现过度拟合的现象。
普通线性回归分析是机器学习中最简单好用的算法之一。该方法让机器通过最小二乘法构建线性回归模型找到最佳拟合线的过程就可以看作是机器找到最好的规律的过程。但在之前的章节也学习到了,普通的线性回归存在过度拟合的现象,特别是当样本量比较小的时候,这个缺点尤为突出。过度拟合是指机器学习了过多的特征,它不仅学习到了全局特征,还学习到了样本才有的局部特征(噪音)。为了消除这个缺点对算法的影响,我们在此引入惩罚线性回归方法。这种方法通过“正则化(Regularization)”,即在目标函数中加入一些规则或限制,如增加惩罚项或降低自由度等以实现最佳回归结果。因此,在一般线性回归中加入惩罚项的算法就叫做惩罚回归。惩罚项的作用在于随着模型中包含的非零的自变量个数增加时,惩罚力度上升进而使得实现目标的概率下降。
所以当存在很多自变量的时候,我们偏向于使用这个模型。