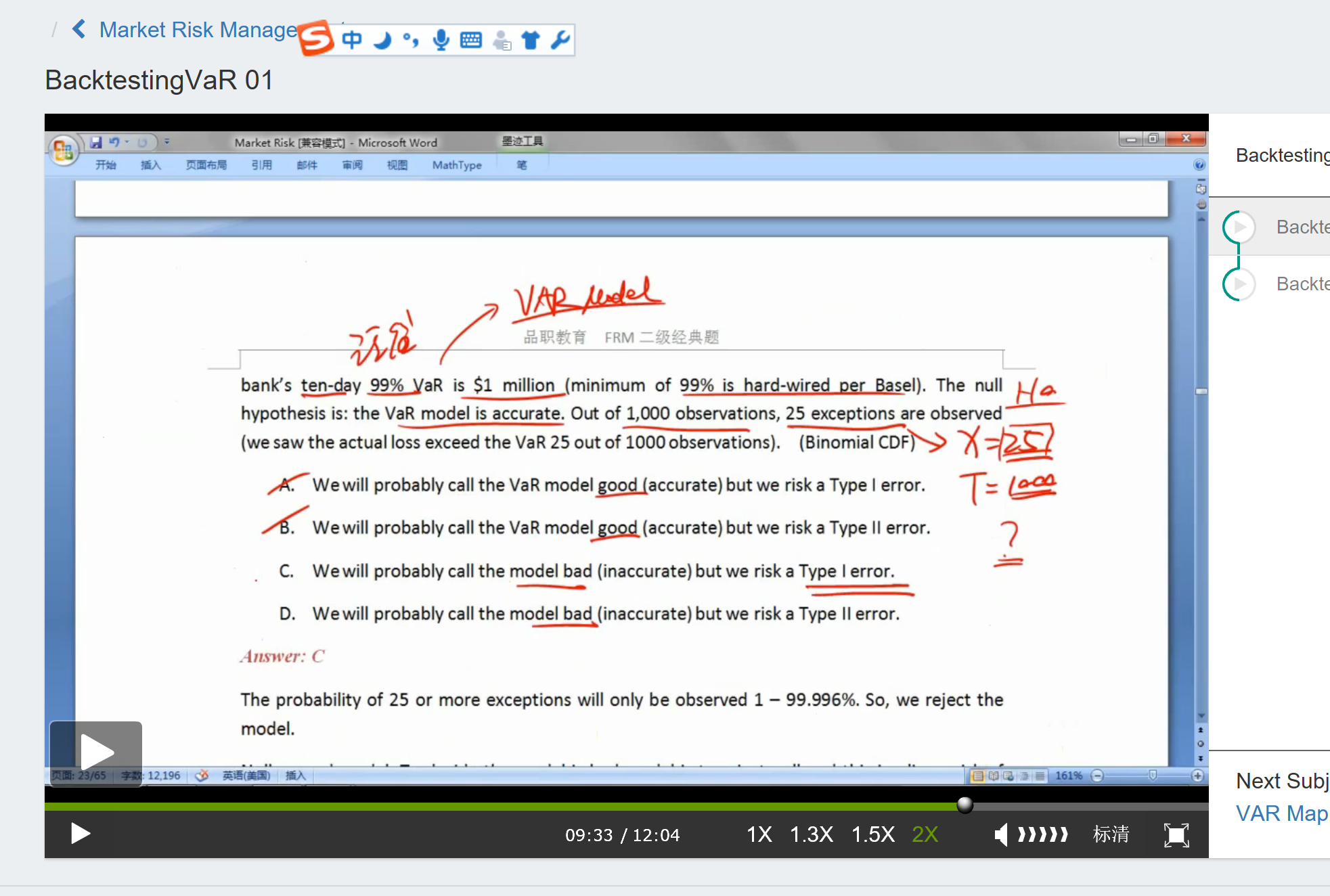
我问几个问题:backtesting的题,一般给两个x%,一个是VAR model的,假如说n为250,VAR为95%,confidence level为90%,exception为19,那么(1)5%是failure rate?是不是凡是超过VAR就叫做failure rate?但是为什么exception是19个,而不是5个?那意思是不是5%的可能性,exception的个数为19?(2)第二个90%就是confidence level,置信区间,是用来做backtesting的,那么confidence level+significance level是否=1?(3)VAR的95%,如果变小,那么failure rate会变大,我理解,但是为啥exception也变大?(4)例外增多,是由于区间涵盖的区间变小造成的,为何说是因为N增多造成的呢?(5)VAR的x%对type 1和2 error的影响,只在于N变多,所以两种错误几率都变小?为何会是VAR的x%代表type 1 error的概率?(6)Mr-经典题P16-1.2题-计算出来的t大于x%对应的值,则落在拒绝域。拒绝原假设(原假设为真),所以计算结果说明模型并不准确。第一类错误和第二类错误的含义,我是明白的,我不明白的是,从题目哪里可以看出来,我们以真为假了,模型本身不就是bad的吗、?