


1/HHI 得到的effective number of stock 是跟benchmark number of stock 越接近tracing error越小,还是考虑越接近之后tading cost 大,tacking error 反而大了?
下面两题关于股票数量的选择矛盾


笛子_品职助教 · 2023年09月05日
嗨,从没放弃的小努力你好:
下面两题关于股票数量的选择矛盾
1/HHI 得到的effective number of stock 是跟benchmark number of stock 越接近tracing error越小,还是考虑越接近之后tading cost 大,tacking error 反而大了?
股票数量不矛盾哦。因为前提条件不同。
这两个benchmark:一个是流动性很差的mid cap指数。一个是流动性极高,都是大盘股的标准普尔指数。
我们先看知识点:
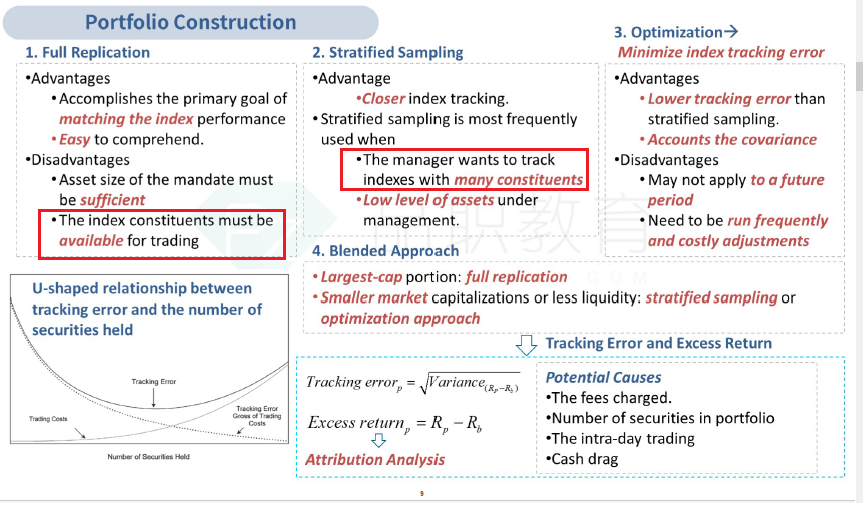
full replication要求available for trading,意思是,benchmark里,都是流动性很好的大盘股。
那么,对于mid cap index,由于流动性很差,并不适合使用full replication方法。
因此这里都不需要看股票数量,full replication方法只要一运用到mid cap 中,就已经决定了trakcing error会比较高。
对于标准普尔指数,因为该指数里包含了流动性最好,盘子最大的500只股票。因此这里的tracking error都不会很高。
475只股票还是504只股票,差别都不会很大。
同学很可能受到U曲线的迷惑。认为股票数量越多,trakcing error也越大。
老师举个反例:
道琼斯工业30指数,有30只股票。
portfolioA,复制了道琼斯工业30指数,买了30只股票。
portfolioB,只买了1只股票。
问portfolioA和portfolioB,哪个trakcing error大。
结论是:股票数量更多的portfolioA,trakcing error更小。股票数量更少的portfolioB,tracking error更大。
为什么会有这个反例呢?这是因为:这个结论,是有多个前提的,在不满足这些前提的时候,这个结论并不成立。
首先的前提,我们要求指定使用full replication方法,如果使用的是别的方法,这个结论不成立。
其次的前提,benchmark必须是股票数量极多,并且benchmark里有很多流动性较差的中小盘股。如果不是这种benchmark,这个结论也不成立。
U曲线,更多的是为了引出抽样和最优化的方法。
当股票数量多,我们使用full replication方法,会造成trakcing error加大,因此,这个时候我们需要放弃full replication,使用抽样或最优化。
一旦我们使用了抽样或最优化的方法,那么“股票数量越多,trakcing error也越大”就直接不成立了。
也正是这个原因,这个结论,很少用于解题之中。
因此:当benchmark都是流动性极好的大盘股时(比如标准普尔500指数),portfolio的持仓数量与benchmark越接近,则trakcing error越小。
----------------------------------------------
加油吧,让我们一起遇见更好的自己!