NO.PZ2021083101000014
问题如下:
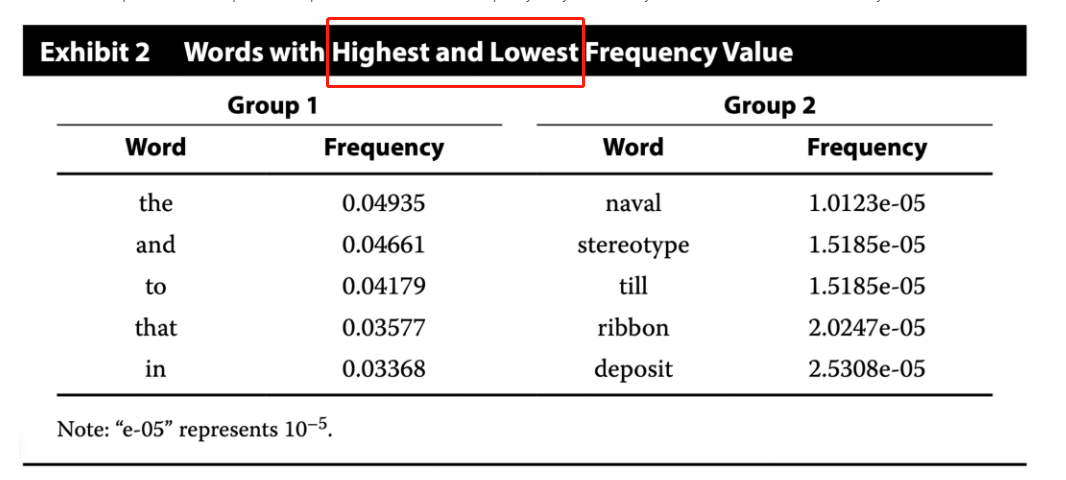
As an additional part of the text exploration step, Achler conducts a term frequency analysis to identify outliers. Achler summarizes the analysis in Exhibit 2.

Based on Exhibit 2, Achler should exclude from further analysis words in:
选项:
A.
only Group 1
B.
only Group 2
C.
both Group 1 and Group 2
解释:
C is correct.
Achler should remove words that are in both Group 1 and Group 2. Term frequency values range between 0 and 1. Group 1 consists of the highest frequency values (e.g., “the” = 0.04935), and Group 2 consists of the lowest frequency values (e.g., “naval” = 1.0123e–05).
Frequency analysis on the processed text data helps in filtering unnecessary tokens (or features) by quantifying how important tokens are in a sentence and in the corpus as a whole.
The most frequent tokens (Group 1) strain the machine-learning model to choose a decision boundary among the texts as the terms are present across all the texts, which leads to model underfitting.
The least frequent tokens (Group 2) mislead the machine-learning model into classifying texts containing the rare terms into a specific class, which leads to model overfitting. Identifying and removing noise features is critical for text classification applications.
A is incorrect because words in both Group 1 and Group 2 should be removed.
The words with high term frequency value are mostly stop words, present in most sentences. Stop words do not carry a semantic meaning for the purpose of text analyses and ML training, so they do not contribute to differentiating sentiment.
B is incorrect because words in both Group 1 and Group 2 should be removed.
Terms with low term frequency value are mostly rare terms, ones appearing only once or twice in the data. They do not contribute to differentiating sentiment.
考点:Unstructured Data Exploration
frequency不是0—1吗?!Group 1这些词的频率是0.0几,不算高吧?