袁园_品职助教 · 2022年06月07日
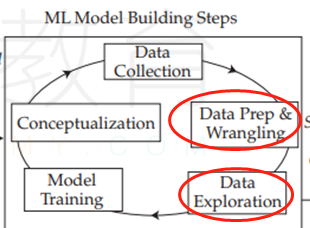
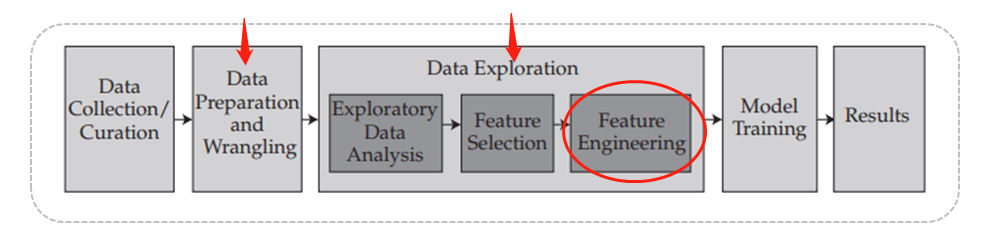
Data preprocessing(wrangling)是数据预处理,然后下一个步骤是Data Exploration(数据探索),这里面一个环节是feature engineering(特征工程)。

数据预处理里面有一个步骤叫做:数据提取(Extraction)。指从现有的变量中,提取出一组新的变量。例如之前的表格中,将“出生日期”直接用于分析并不直观,这个时候就可以据此新提取出一个变量“年龄”。
数据探索里面的特征工程: 特征工程指在特征选择的基础上,将各个特征做了进一步的优化。创造出了新的更便于训练模型的特征。例如可以将几个特征相乘后取对数,形成一个新的特征。或者将一个原特征拆分为几个新特征。优化后的特征可以更好的描述数据之间的规律性。特征工程可以降低欠拟合的问题。
这两者的区别:特征工程是基于特征选择的基础上,相比于之前那个数据提取要复杂很多。因为特征选择需要对于数据集有一个深刻的了解后才能进行选择并删除局部特征。此外,也可以通过统计学方法等将特征的重要性进行排序,只保留最重要的特征。
所以按照你的理解,同样是创造一个变量,但是这个层次是不一样的,数据提取只是一个预处理,简单的把出生日期变成年龄,但是特征工程要复杂很多,首先要对所有数据集进行深刻了解,然后做特征选择,再做特征工程,比如还是出生日期这个例子,特征工程需要判断这个出生日期是不是最重要的特征(特征选择),如果保留下来做特征工程,类似于创造出70年代、80年代、90年代这种类似的新变量,比之前那个年龄更加进一步哦。所以所处的步骤也要更加的靠后哦。