
做过的题你都能拿分吗?
临近考试,小编相信大家都开始启用“题海”战术,疯狂刷题,可是你现在做过的题,你考场碰到都能做对吗?
同为备考党的我,小编只想说,如果只做过一遍,那怕是有点难。

我相信大家都是从题海战术里走出来的朋友们,这其实就是一个熟能生巧的事情,即时可能你对某个知识点不理解,但是同一个题型你做完3次后,就有一种闭着眼睛我都能认出你的熟悉感,剥掉题干的外壳,其实都是同一个套路。
那么到底哪些题目是有典型考法的,哪些知识点是比较易错的点,这就是大家考前需要拿个小本本记下来的事情。
看到这里,是不是大家都有一种蠢蠢欲动,要赶紧去做笔记的想法?

知道目前大家都在争分多秒学习,贴心的品职教研组的小哥哥、小姐姐们也是熬夜赶工(心疼一下),帮大家整理了CFA三个级别学科的错题本,希望在最后的时候能给大家起到助力的作用。
在接下来的几周里,我们会陆续发放三个级别的高频问答,希望对大家的备考有所帮助。今天二级放上数量的错题本,大家一起来看看这些题都会做吗?


精选问答1
题干
A factor associated with the widespread adoption of algorithmic trading is increased:
A. market efficiency.
B. average trade sizes.
C. trading destinations.
答案解析
C is correct.
Global financial markets have undergone substantial change as markets have fragmented into multiple trading destinations consisting of electronic exchanges,alternative trading systems, and so-called dark pools.
In such an environment,when markets are continuously reflecting real-time information and continuously changing conditions, algorithmic trading has been viewed as an important tool.
解题思路
这题考察的是算法交易的内容。题目问的是,下面哪个现象的增加是导致算法交易的广泛使用的原因?
![]() A选项,市场有效性的增加。这个其实并不是导致算法交易广泛应用的原因,而是算法交易广泛应用所导致的结果。比如我们使用高频交易,可以快速获得信息,对市场做出反应,可以快速纠正整个市场价格出现错误定价的现象,得到一个更好的市场有效性。
A选项,市场有效性的增加。这个其实并不是导致算法交易广泛应用的原因,而是算法交易广泛应用所导致的结果。比如我们使用高频交易,可以快速获得信息,对市场做出反应,可以快速纠正整个市场价格出现错误定价的现象,得到一个更好的市场有效性。
![]() B选项,交易规模的增加。这个也是算法交易广泛应用所导致的结果。因为有了高频交易之后,交易频率更高,导致市场流动性在增加,从而导致交易规模的增加。
B选项,交易规模的增加。这个也是算法交易广泛应用所导致的结果。因为有了高频交易之后,交易频率更高,导致市场流动性在增加,从而导致交易规模的增加。
![]() C选项,交易的地点的增加。正是因为交易的地点越来越多,一只股票可能会在多个交易所进行交易,所以对于信息处理的要求在进一步增加,所以算法交易才会被广泛使用。所以正确答案是C选项。
C选项,交易的地点的增加。正是因为交易的地点越来越多,一只股票可能会在多个交易所进行交易,所以对于信息处理的要求在进一步增加,所以算法交易才会被广泛使用。所以正确答案是C选项。
易错点分析
这道题很多人都容易出错,确实考的也是比较细的知识点。这道题目有个陷阱就是,考的是导致算法交易的广泛使用的原因,而不是算法交易广泛应用所导致的结果。这里就很难进行区分,也是很多人的疑惑点。Fintech的题目都是一些文字概念题,也是2019年新增的知识点,对于这部分内容还是需要再去浏览一遍讲义进行理解记忆。
精选问答2
题干
If an omitted variable is correlated with variables already included in the model,coefficient estimates will be biased and inconsistent and standard errors will also be inconsistent. Is this Statement correct?
A. Yes.
B. No, because the model’s coefficientestimates will be unbiased.
C. No, because the model’s coefficientestimates will be consistent.
答案解析
A is correct.
Changis correct because a correlated omitted variable will result in biased andinconsistent parameter estimates and inconsistent standard errors.
解题思路
如果遗漏了一项跟已有变量相关的变量,那么说明这个建好的模型的残差项包含了跟自变量有关系的那个变量,那么也就是自变量和残差项相关,就不满足模型的前提假设了,才会引发之后的一系列影响。所以这道题目考的其实是model Misspecification,并不是多重共线性。
易错点分析
这道题目很多同学都会自动联系到多重共线性的情形,所以很容易选错答案。但其实这题只是说遗漏了一个重要变量,但又还没有达到多重共线性所要求的相关系数大于0.7的那么重要,所以如果考察的是多重共线性,那么在题目中一定是会有相对应的描述的。
所以这题其实考的并不是违反的三个假设,而是model Misspecification的第一条,重要变量的遗漏。这里要注意区分,不要弄混了。
精选问答3
题干
Varden answers both questions correctly and says he wants to check two more ideas. He believes the following:
![]() ROE is less correlated with the dividend growth rate in firms whose CEO has been in office more than 15 years, and
ROE is less correlated with the dividend growth rate in firms whose CEO has been in office more than 15 years, and
![]() CEO tenure is a normally distributed random variable.
CEO tenure is a normally distributed random variable.
If Varden’s beliefs about ROE and CEO tenure are true, which of the following would violate the assumptions of multiple regression analysis?
A. The assumption about CEO tenure distribution only.
B.The assumption about the ROE/dividend growth correlation only.
C. The assumptions about both the ROE/dividend growth correlation and CEO tenure distribution.
答案解析
C is correct.
Multiple linear regression assumes that the relationship between the dependent variableand each of the independent variables is linear.
Varden believes that this is not true for dividend growth because he believes the relationship may be different in firms with a long-standing CEO.
Multiplelinear regression also assumes that the independent variables are not random.Varden states that he believes CEO tenure is a random variable.
解题思路
对于第一条,他认为,CEO超过15年的公司的股息增长率与ROE的关系较弱。说明股息增长率与ROE的关系不稳定,并且取决于CEO的在任时长,那么这就违背了自变量与因变量之期间呈现线性关系的假设。
对于第二条,他认为,CEO的任期是正态分布随机变量。那就违反了自变量不是随机变量这个假设。
所以综上所述,以上两条都会违反多元回归分析的假设。
易错点分析
这道题目大家出错比较多,主要是因为没有看懂题目在说什么。对于回归的假设这一知识点,很多同学很容易遗忘,当放在case题里面考察的时候,一下子就反应不过来了。
除了这题,其实很多题都会建立在回归检验的假设上来出题,并不是只考察单一的知识点。所以对于回归分析的前提假设,我们还是要做到牢记于心的,当遇到不知从何下手的题目,也许这就是一个突破点。
精选问答4
题干
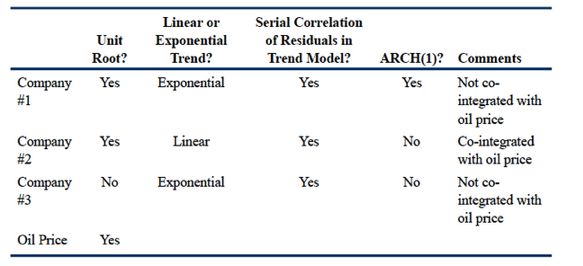
Which single time-series model would most likely be appropriate for Busse to use inpredicting the future stock price of Company #3?
A. Log-linear trend model.
B.First-differenced AR(2) model.
C. First-differenced log AR(1) model.
答案解析
C is correct.
As a result of the exponential trend in the time series of stock prices for Company #3, Busse would want to take the natural log of the series and then first-difference it.
Because the time series also has serial correlation in the residuals from the trend model, Busse should use a more complex model, such asan autoregressive (AR) model.
解题思路
对于这道题,我们要用排除法来做。首先对于A选项,因为公司3的信息表明,残差项是存在一个序列相关的现象的,所以我们是不能使用趋势模型来进行预测的。这就排除了A选项。
这时候我们发现,B和C的答案里面都包含有一阶差分,很多人会问,为什么没有单位根的现象也需要有一阶差分,这里确实是题目出的不太严谨,因为A选项很容易就能排除,所以我们只能在B和C中间选出相对正确的一项。
我们再去看公司3的信息,可以发现公司3的价格是呈现一个指数型的趋势的,而只有C选项体现了这一点,所以相对来说,C选项会更好一些。
易错点分析
这道题目考的比较偏,确实也有不严谨的地方。但是就做题而言,当我们真的碰到这种题目,我们就得采取特定的方法,对于这道题而言就可以采用排除法来做。原版书这道题其实也是想让大家在给出的三个模型里面选出一个相对而言最好的模型,但这并不意味着我们只能用这个模型来预测。
对于考试而言,我们的目标是选出正确答案。当然对于这个知识点而言,我们还是需要掌握什么时候应该一阶差分,什么时候要用AR模型等等。所以不用太纠结于这道题。
精选问答5
题干
He also believes that for each 1 percent increase in pre-offer price adjustment,the initial return will increase by less than 0.5 percent, holding other variables constant. Hansen wishes to test this hypothesis at the 0.05 level of significance.
Hansen collects a sample of 1,725 recent IPOs for his regression model.
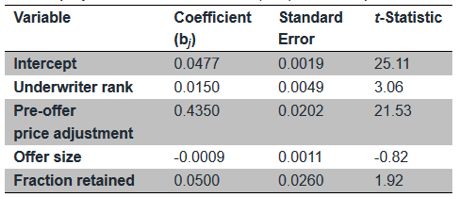
Hansen’s Regression Results Dependent Variable: IPO Initial Return (Expressed in DecimalForm, i.e., 1% = 0.01)
The most appropriate null hypothesis and the most appropriate conclusion regarding Hansen’s belief about the magnitude of the initial return relative to that ofthe pre-offer price adjustment (reflected by the coefficient bj) are:
Null Hypothesis Conclusion about bj(0.05 Level ofSignificance)
A. H0:bj=0.5 Reject H0
B. H0: bj≥0.5 Fail to reject H0
C. H0:bj≥0.5 Reject H0
答案解析
C is correct.
To test Hansen’s belief about the direction and magnitude of the initial return,the test should be a one-tailed test. The alternative hypothesis is H1: bj<0.5, and the null hypothesis is H0: bj≥0.5 .
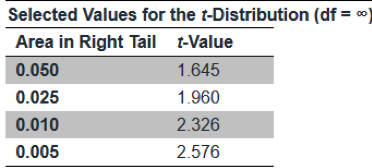
The correct test statistic is: t =(0.435-0.50)/0.0202 = -3.22, and the critical value of the t-statistic for aone-tailed test at the 0.05 level is -1.645. The test statistic is significant,and the null hypothesis can be rejected at the 0.05 level of significance.
解题思路
首先我们要知道,题干给的表格,都是基于(b-0)/SE计算出来的。但是在题干中描述了这个人的猜想,这个人有百分之95的自信猜在其他变量不变的情况下自变量pre-offer priceadjustment每增加百分之1,Y的增加会少于百分之0.5,也就是说有百分之95的自信心猜测当其他条件不变,Y的增加量会低于0.5%,所以这个是我相信的,放在备择假设,然后原假设是我想拒绝的,也就是Y的增加了会大于等于0.5%。
所以原假设就是:H0:bj≥0.5。再来看是否要拒绝原假设,因为题干给的表格是默认b等于0的,所以这里我们就不能直接用题干表格数据的t统计量来得出答案了。
我们需要重新计算一下t统计量。t = (0.435-0.50)/0.0202= -3.22。接下来就是跟临界值比较,这里查表也需要注意,题目给的是右尾的面积,因为根据原假设,我们的检验是一个单尾检验,但是是左尾检验。不过由于对称性,右尾的面积等于0.05的临界值是1.645,那么左尾的面积等于0.05的临界值就等于-1.645。
已知t统计量的绝对值大于临界值的绝对值,所以我们应该拒绝原假设,所以答案选C。
易错点分析
这题考的比较灵活,还放置了陷阱,以至于同学们很容易就跳进这个陷阱里,从而选择了错误的答案。因为我们做的可以说95%的题目,都是默认检验系数是否等于0的,所以看到题目时,同学们就会条件反射的也这么默认了。但这道题又给了大家提示,如果答案里出现一个bj≥0,这时候又会引起混淆了。
所以虽然题目挖了一个陷阱,但是又给了大家一条绳索,就看能不能抓住这条绳索成功获救了。但对于这道题呢,即使没有计算新的t统计量的值,用了表中的数据,我们也能碰巧选出正确答案,这就是选择题的优势。但是我们不能存在这种侥幸心理,还是要仔细读题,画出关键信息,因为下一次也许就不会让大家这么轻易的选出正确答案啦。
还有一点,很多人都会问考试的时候会不会让我们查表,需不需要记住这些临界值。这里也跟大家统一说一下,考试的时候一般都会直接给出临界值,当然也有可能会像这道题一样,给表格的一部分,让我们进行查表。所以我们还是要掌握好查表的方法,区分单尾双尾,这也是大家很容易混淆的地方。




